
PostgreSQL merupakan salah satu open ssource database yang cukup mature dan cukup luas digunakan untuk berbagai keperluan dari tradisional OLTP atau OLAP. Dari sisi kinerja, sebagai database yang telah mature teknologinya, PostgreSQL sudah tidak lagi diragukan. Untuk kemampuan mengolah/menyimpan data, menurut laporan ComputerWorld, Yahoo Inc. telah menggunakan PostgreSQL yang dimodifikasi untuk keperluan Data Ware House. Dari hasil modifikasi yang merubah penyimpanan dari row based menjadi column based, Yahoo Inc. telah mengoperasikan PostgreSQL dengan besar data 2 peta-byte, atau 2.000 terra-byte, atau 2.000.000 giga-byte, atau 2.000.000.000 mega-byte!!! Kita doakan saja Yahoo Inc. bersedia merilis postgreSQL yang telah mereka modifikasi ke komunitas pengguna postgreSQL. Hal yang masih menghantui para pengguna PostgreSQL adalah masalah replikasi. Sebenarnya banyak alternatif yang ditawarkan untuk mengimplementasikan replikasi pada PostgreSQL. Setidaknya beberapa yang sudah kita kenal diantaranya: PGCluster, PGPool, Sequoia, Slony-I. Namun, di sini saya hanya akan membahas secara mendalam untuk 2 teknologi replikasi. PGCluster dan Slony-I, karena kebanyakan referensi mengarah kepada PGCluster dan Slony.
PGCluster
Merupakan statement based multi master replication, namun tidak melakukan pooling terhdap statement. PGCluster melakukan modifikasi terhadap paket source PostgreSQL sehingga memungkinkan melakukan komunikasi antar node untuk saling me-replay setiap statement yang diterima dari node lain. Sesuai dengan namanya, PGCluster mempunyai kemampuan load balancing, sehingga bias melakukan pembagian tugas antar node. Hal yang dirasa kurang dari PGCluster adalah ketidakhadiran statement queuing yang akan mengatur queue suatu statement yang akan direplay oleh suatu node. Hal ini akan menuntut suatu transaksi untuk bisa commit pada semua node yang terlibat, atau, stag! Oleh karena itu pada konfigurasi pgCluster ada satu item yang memungkinkan untuk merubah satu node menjadi hanya readonly (untuk superuser sekalipun) pada kondisi standalone (tidak terhubung dengan node lain). Ini dilakukan untuk menjaga integritas data oleh karena ketidak hadiran statement queuing yang bisa menggaransi data sampai kepada subscriber bagaimanapun kualitas jaringan komunikasi yang ada (pada batas logis tentunya).
Gambar Logic PGCluster

Pada gambar terlihat bahwa secara logic pada suatu cluster yang melibatkan dua database (ClusterDB), akan menyertakan 3 server lain yang meliputi Load Balancer, Replicator 1, dan Replicator 2.
Pada kondisi riil, bergantung kepada kebutuhan, gambar di atas bisa disederhanakan menjadi hanya 2 server. Replicator 1 bisa digabung dengan ClusterBD 1 sementara Replicator 2 digabung dengan ClusterDB 2. Load Balancer, bergantung kepada kebutuhan, apa bila koneksi diarahkan dari ClusterDB 1, maka load balancer bisa dibenamkan kedalam installasi ClusterDb 1. Pada kondisi dimana justeru load balancer tidak dibutuhkan, maka Load Balancer bisa ditiadakan.
1. Installasi PGCluster
PGCluster bukan merupakan aplikasi terpisah dari PostgreSQL, namun merupakan modifikasi dari PostgreSQL dengan tujuan memberikan fitur clustering/replication. Untuk itu hal yang harus diperhatikan adalah, jika kita akan melakukan clustering terhadap existing database maka kita harus mengambil PGCluster yang sesuai dengan versi dari existing database kita. Misal, kita menggunakan PostgreSQL 8.3, maka kita harus menggunakan PGCluster ver. 1.9 yang dibangun berdasar versi 8.3.
Kita bisa mendownload PGCluster dari link berikut ini http://pgfoundry.org/projects/pgcluster/
Dalam contoh kali ini, akan digunakan PostgreSQL 8.3 sehingga versi PGCluster yang digunakan adalah versi 1.9 Link http://pgfoundry.org/frs/download.php/2408/pgcluster-1.9.0rc7.tar.gz
Untuk lab kita kali ini, akan melibatkan 1 PC (1 IP address) dengan dua PostgreSQL, 1 Load Balancer dan 1 replicator. Gambaran dari konfigurasi untuk lab ini bisa dilihat pada gambar berikut:

Pertimbangan untuk memilih strategi ini adalah bahwa kondisi aplikasi yang akan kita tangani tidak mendukung dijalankannya load balancer yang memungkinkan result diambil bukan dari satu tempat tertentu. Ini berbahaya untuk pembentukan nomor pendaftaran pada aplikasi yang akan ditangani.
Langkah installasi
Persiapan
Untuk menjalankan pgcluster, sangat disarankan untuk tidak menggunakan root user, dan untuk itu kita harus menyediakan user pgcluster dengan menjalankan perintah
root@myhost~$: su – pgcluster [change user ke pgcluster]
pgcluster@myhost~$:cd pgcluster-1.9.0rc7 [masuk ke direktori source]
pgcluster@myhost~$:./configure --enable-thread-safety -–prefix=/opt/pgc/pgcluster
[konfigure kompilasi source. --prefix akan mengarah proses installasi kepada direktory /opt/pgc/pgcluster. Jika tidak disebutkan, maka akan diarahkan ke /usr/local/pgsql]
pgcluster@myhost~$:make all [compail source menjadi executable dan library]
pgcluster@myhost~$:make install [install executable ke direktory yang telah disebutkan di prefix]
Inisiasi Database
pgcluster@myhost~$:vi ~/data2/postgresql.conf [edit postgresql.conf untuk data2]
Cari line untuk config value port [pada line 60]. Hapus '#' character di depan 'port' dan rubah 5432 menjadi 5433.
Catatan: Untuk onfigurasi riil dengan lebih dari 1 mesin atau slave terinstall di mesin yang lain maka listener port masih boleh dipertahankan pada port 5432 (default port postgreSQL)
Edit cluster.conf untuk master (~/data1) dan slave (~/data2)
<replicate_server_info>
<host_name> replicat1.pgcluster.org </host_name>
<port> 8001 </port>
<recovery_port> 8101 </recovery_port>
menjadi
#-------------------------------------------------------------
<host_name> localhost </host_name>
<recovery_port> 7001 </recovery_port>
<rsync_path> /usr/bin/rsync </rsync_path>
<rsync_option> ssh -2 </rsync_option>
<rsync_compress> yes </rsync_compress>
<rsync_timeout> 10min </rsync_timeout>
<rsync_bwlimit> 0KB </rsync_bwlimit>
<pg_dump_path> /usr/local/pgsql/bin/pg_dump </pg_dump_path>
<ping_path> /bin/ping </ping_path>
<when_stand_alone> read_only </when_stand_alone>
<replication_timeout> 1min </replication_timeout>
<lifecheck_timeout> 3s </lifecheck_timeout>
<lifecheck_interval> 11s </lifecheck_interval>
Menjadi
pgcluster@myhost~$:cp /opt/pgc/pgcluster/share/pgreplicate.conf.sample ~/data1/pgreplicate.conf
Catatan: Pada kondisi riil, kopikan ke direktori data pada mesin master.
Edit dengan menggunakan vi
<cluster_server_info>
<host_name> master.pgcluster.org </host_name>
<port> 5432 </port>
<recovery_port> 7001 </recovery_port>
</cluster_server_info>
<cluster_server_info>
<host_name> clusterdb2.pgcluster.org </host_name>
<port> 5432 </port>
<recovery_port> 7001 </recovery_port>
</cluster_server_info>
menjadi
#-------------------------------------------------------------
<host_name> localhost </host_name>
<replication_port> 8001 </replication_port>
<recovery_port> 8101 </recovery_port>
<rlog_port> 8301 </rlog_port>
<use_replication_log> no </use_replication_log>
<replication_timeout> 1min </replication_timeout>
<lifecheck_timeout> 3s </lifecheck_timeout>
<lifecheck_interval> 15s </lifecheck_interval>
#-------------------------------------------------------------
Bagian yang dicetak tebal akan digunakan untuk menentukan setting pada cluster.conf
Test Konfigurasi
Jalankan database
pgcluster@myhost~$:/opt/pgc/pgcluster/bin/psql -h localhost -d postgres [menjalankan interactive sql ke localhost port 5432 user pgcluster (sesuai login os) database postgres]
Welcome to psql 8.3.8, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
postgres=#
[koneksi berhasil]
pgcluster@myhost~$:/opt/pgcluster/bin/psql -h localhost [menjalankan interactive sql tersambung ke localhost default port (5432) user pgcluster (default sesuai login os) db pgcluster (default sesuai db user)]
psql: FATAL: database "pgcluster" does not exist [pesan kesalahan menunjukan bahwa database pgcluster tidak diketemukan pada localhost port 5432 (master) ]
pgcluster@myhost~$:/opt/pgcluster/bin/psql -h localhost -p 5433 [menjalankan interactive sql tersambung ke localhost port 5433 user pgcluster (default sesuai login os) db pgcluster (default sesuai db user)]
psql: FATAL: database "pgcluster" does not exist [pesan kesalahan menunjukan bahwa database pgcluster tidak diketemukan pada localhost port 5433 (slave) ]
Test Replikasi
pgcluster@myhost~$:/opt/pgcluster/bin/psql -h localhost | [ -p 5433]
Welcome to psql 8.3.8, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help with psql commands
\g or terminate with semicolon to execute query
\q to quit
pgcluster=#
Seharusnya baik ke port 5432 maupun ke port 5433 (master maupun slave) akan memberikan hasil yang sama.
Untuk memastikan jalankan perintah berikut
CREATE TABLE
[response dari server database]
Check ke dataserver 5432.
no | nama
----+------
(0 rows)
Check ke dataserver 5433
pgcluster@mastoyo:~$ /opt/pgc/pgcluster/bin/psql -h localhost -p 5433 -c "select * from testtable"
no | nama
----+------
(0 rows)
Test insert data
INSERT 0 1
Check ke dataserver 5432
no | nama
----+-----------
1 | test nama
(1 row)
Check ke dataserver 5433
no | nama
----+-----------
1 | test nama
(1 row)
Slony
Slony merupakan aplikasi yang murni berfungsi sebagai replication server. Berbeda dengan pgCluster, slony tidak mendukung load balancing. Slony bukanlah statement based replication meskipun yang direplikasikan merupakan statement, tetapi hanya transaksional statement., sedangkan DDL tidak akan direplikasikan. slony adalah table based replication dan setiap table yang akan direplikasikan harus didefinisikan terlebih dahulu. Statement yang akan direplikasikan terlebih dahulu akan disimpan dalam dalam suatu skema yang didefinisikan dalam 'Cluster'. Adanya skema ini akan mampu menggaransi bahwa data yang akan direplikasi akan sampai ke subscriber. Artinya dalam situasi terjadi gangguan terhadap komunikasi, statement masih tersimpan didalam 'Cluster'. Ketika komunikasi telah pulih, proses replikasi akan kembali diteruskan untuk setiap statement yang belum tereplikasi. Secara garis besarnya proses replikasi dengan menggunakan Slony bisa dikatakan masih lebih bisa lebih diandalkan.
Sampai saat ini, slony menjalankan 2 project. Slony-I replication project master-slave. Slony-II replication project untuk master-master.
Untuk kepentingan saat ini, kita akan menggunakan Slony-I. Hampir sama dengan konfigurasi yang kita pakai dalam membentuk replikasi dengan menggunakan pgCluster, applikasi yang akan kita replikasikan datanya memang masih belum mendukung diimplementasikannya load balancing yang membutuhkan konfigurasi master-master. Disamping itu dalam situasi bencana di DC, tentunya juga tidak membutuhkan replikasi balik dari situs DRC ke situs DC karena DC nya sendiri tidak operasional.
Gambar logic Slony
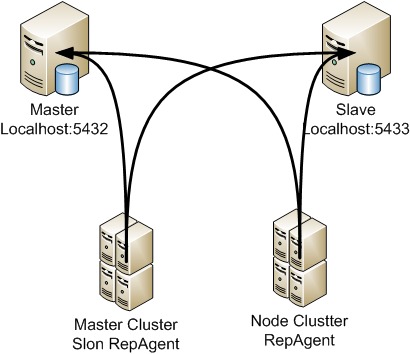
Gambar di atas digambarkan untuk kondisi lab yang menggunakan satu server dengan satu IP (localhost).
Dari gambar di atas bisa dilihat bahwa Master database akan dijalankan dan listening di port 5432 sedang Slave database listening di port 5433. Replication agen (slon) kemudian dijalankan untuk terkoneksi ke slave (jika master) dan ke master (jika slave).
Persiapan
Sebelum kita lanjutkan untuk setup replikasi terlebih dahulu kita harus mengenal beberapa hal mengenai slony.
Cluster kumpulan node yang berpartisipasi pada proses replikasi dengan menggunakan slony.
Node adalah entity yang unik yang terdiri dari kombinasi IP address, Port, dan database.
Path adalah informasi koneksi antara cluster dan node.
Replication Set adalah sekumpulan table, dan secara opsional sequence object dimana data akan direplikasikan.
Master adalah asal dari data yang akan direplikasikan.
Slave atau juga sering disebut sebagai subscriber.
Provider adalah node yang menyediakan data yang akan direplikasikan
Cascaded Subscription adalah konfigurasi dengan minimal ada satu node yang berfungsi sebagai Provider sekaligus Subscriber.
Slon. Slony daemon yang akan mengontrol proses replikasi. Untuk linux setiap node memiliki slon – nya masing-masing, sedangkan untuk Windows hanya ada 1 slon service dalam satu host.
Slonik, program utility yang digunakan untuk memproses perintah untuk membuat dan mengupdate konfigurasi.
Penyiapan postgreSQL engine.
PostgreSQL engine bisa kita dapatkan dari berbagai sumber. Saya lebih menyarankan untuk menginstall langsung dari source program daripada binary. Source program bisa didapatkan langsung dari http://www.postgresql.org maupun dari beberapa repository local seperti http://kambing.ui.ac.id. Dalam lab ini, kita akan menggunakan PostgreSQL versi 8.3.0 dengan Slony-I versi 1.2.21.
Berbeda dengan pgCluster, Slony-I adalah aplikasi terpisah dari PostgreSQL atau dengan kata lain, dikembangkan terpisah bukan pengembangan PostgreSQL, sehingga kita bisa menggunakan source normal PostgreSQL.
Sebagaimana pgCluster, untuk menjalankan postgreSQL sangat disarankan untuk menggunakan non-root user sehingga kita harus mempersiapkan terlebih dahulu user yang akan kita pergunakan untuk menjalankan postgreSQL. Apabila, kita melakukan installasi dari sumber binary (tanpa melalui proses kompilasi), maka bisa kita lihat bahwa user 'postgres' otomatis akan terbentuk. Kita bisa meniru dengan menyediakan user 'postgres' untuk installasi postgreSQL kita.
root@myhost~$:mkdir /opt/pgs [buat home direktory postgres]
root@myhost~$chown postgres:postgres /opt/pgs [Change Ownership dari /opt/pgs kepada postgres]
root@myhost~$:cp /home/myuser/Download/postgresql-8.3.0.tar.bz2 /opt/pgs [kopikan source postgreSQL dari direktori download ke direktori /opt/pgs]
root@myhost~$:cd /opt/pgs [masuk ke direktory /opt/pgs]
root@myhost~$:bunzip2 postgresql-8.3.10.tar.bz2 [extract file menjadi tarball file]
root@myhost~$:tar -xvf postgresql-8.3.10.tar [extract tarball file]
root@myhost~$chown postgres:postgres /opt/pgs -Rv [Change Ownership dari semua file di bawah /opt/pgs kepada postgres]
root@myhost~$:su – postgres [switch user ke postgres]
postgres@myhost~$:cd postgresql-8.3.10 [masuk ke direktori postgresql-8.3.10]
postgres@myhost~$:./configure --prefix /opt/pgs/pgsql [konfigurasi untuk kompilasi source postgresql]
postgres@myhost~$:make all [menjalankan proses kompilasi source menjadi binary executable files]
postgres@myhost~$:make install [menjalankan proses installasi ke direktori yang telah di tentukan]
Installasi Slony-I dari source code
# ~/.profile: executed by the command interpreter for login shells.
# This file is not read by bash(1), if ~/.bash_profile or ~/.bash_login
# exists.
# see /usr/share/doc/bash/examples/startup-files for examples.
# the files are located in the bash-doc package.
# the default umask is set in /etc/profile; for setting the umask
# for ssh logins, install and configure the libpam-umask package.
#umask 022
# if running bash
if [ -n "$BASH_VERSION" ]; then
# include .bashrc if it exists
if [ -f "$HOME/.bashrc" ]; then
. "$HOME/.bashrc"
fi
fi
# set PATH so it includes user's private bin if it exists
if [ -d "$HOME/bin" ] ; then
PATH="$HOME/bin:$PATH"
fi
if [ -d /opt/pgsql/bin ] ; then
PATH=/opt/pgs/pgsql/bin:$PATH
fi
export CLUSTERNAME=slony_example
export MASTERDBNAME=mst_test
export SLAVEDBNAME=slv_test
export MASTERHOST=localhost
export SLAVEHOST=localhost
export REPLICATIONUSER=postgres
Pada contoh di atas bisa dilihat adanya perubahan environment variable $PATH dan penambahan beberapa environment variable yang meliputi
CLUSTERNAME = namespace atau nama cluster yang akan digunakan untuk mendefinisikan replikasi
MASTERDBNAME = nama database Master pada master engine. Ingat, bahwa Slony melakukan replikasi pada level table.
SLAVEDBNAME = name database pada Slave engine.
MASTERHOST = hostname (IP) dimana master engine terpasang
SLAVEHOST = hostname (IP) dimana slave engine terpasang
REPLICATIONUSER = user setara superuser yang akan digunakan sebagai user yang menghandle replikasi dan si sini kita menggunakan postgres
Setelah kita melakukan penyesuaian pada file profile, untuk mengaktifkan profile, kita lakukan logout dengan menekan Ctrl+D dan swith ke user postgres lagi. Dan check environment variable yang kita set dengan mengetikkan 'env' tanpa tanda kutip yang diteruskan dengan [enter].
Inisiasi Database
Bila semua nilai environment variables sudah terpasang dengan baik, langkah berikutnya dalah menginisiasi database.
#!/bin/sh
slonik << _EOF_
cluster name = $CLUSTERNAME;
#penentuan node yang terlibat dalam replikasi, informasi ini akan dipakai oleh slonik
#untuk melakukan koneksi dengan setiap node
#perhatikan bahwa conninfo tidak menyebutkan password, yang berarti harus ada perubahan
#pada file pg_hba.conf untuk membuka trust connection antar node
node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER';
node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST port=5433 user=$REPLICATIONUSER';
#melakukan inisiasi cluster sebagai 'Master Node')
init cluster ( id=1, comment = 'Master Node');
_EOF_
rubah initcluster.sh menjadi executable:
#!/bin/sh
slonik << _EOF_
#4 Baris-baris berikut adalah pengulangan untuk mengenali cluster
cluster name = $CLUSTERNAME;
node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER';
node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST port=5433 user=$REPLICATIONUSER';
#baris berikut merupakan statement untuk menambahkan node
store node ( id=1, comment = 'Slave Node', event node = 1);
_EOF_
Rubah mode addnode.sh menjadi executable
#!/bin/sh
slonik << _EOF_
#4 baris pertama adalah pengulangan untuk mengenali cluster
cluster name = $CLUSTERNAME ;
node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER';
node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST port=5433 user=$REPLICATIONUSER';
#baris berikut menginformasi arah replikasi dari master ke slave
store path (server = 1, client = 2, conninfo='dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER');
store path (server = 2, client = 1, conninfo='dbname=$SLAVEDBNAME host=$SLAVEHOST port=5433 user=$REPLICATIONUSER');
_EOF_
Rubah mode addpath.sh menjadi executable
#!/bin/sh slonik << _EOF_
#4 baris pertama adalah pengulangan untuk mengenali cluster
cluster name = $CLUSTERNAME ;
node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER';
node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST port=5433 user=$REPLICATIONUSER';
#baris berikut akan memerintahkan slony untuk mengcreate set dengan id=1, origin=1)
create set ( id=1, origin=1, comment='table-tabel terreplikasi');
_EOF_
Rubah mode initset.sh menjadi executable.
#!/bin/sh
slonik << _EOF_
#4 baris pertama adalah pengulangan untuk mengenali cluster
cluster name = $CLUSTERNAME;
node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER';
node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST port=5433 user=$REPLICATIONUSER';
#baris berikut akan memerintahkan slony untuk menambahkan table testtable ke dalam repl. Set)
set add table ( set id=1, origin=1, id=1, fully qualified name='public.testtable' comment='testtable', key='nomor');
_EOF_
Rubah mode addtable.sh menjadi executable
#!/bin/sh
slonik << _EOF_
#4 baris pertama adalah pengulangan untuk mengenali cluster
cluster name = $CLUSTERNAME;
node 1 admin conninfo = 'dbname=$MASTERDBNAME host=$MASTERHOST user=$REPLICATIONUSER';
node 2 admin conninfo = 'dbname=$SLAVEDBNAME host=$SLAVEHOST port=5433 user=$REPLICATIONUSER';
#baris berikut akan memerintahkan slony untuk menambahkan table testtable ke dalam repl. Set)
subscribe set ( id = 1, provider = 1, receiver = 2, forward = no);
_EOF_
Rubah mode addsubscriber.sh menjadi executable
#!/bin/sh
slon $CLUSTERNAME "dbname=$MASTERDBNAME user=$REPLICATIONUSER host=$MASTERHOST" >> slonmaster.log 2>&1 &
Rubah mode startmaster.sh menjadi executable
#!/bin/sh
slon $CLUSTERNAME "dbname=$SLAVEDBNAME port=5433 user=$REPLICATIONUSER host=$MASTERHOST" >> slonslave.log 2>&1 &
Rubah mode startslave.sh menjadi executable
postgres@myhost~$:echo “export TZ=ICT”>>~./profile
Karena ada perubahan setting timezone maka postgreSQL engine yang telah aktif harus direstart untuk bisa menggunakan setting timezone yang baru
Urutan menjalankan file-file setup replikasi.
postgres@mastoyo:~$ psql -d $MASTERDBNAME -c "insert into testtable (nomor,nama,alamat) values (2,'Paman Goble','Jalan Rusak');"
INSERT 0 1
postgres@myhost:~$ psql -d $SLAVEDBNAME -p 5433 -c "select * from testtable;"
nomor | nama | alamat
-------+-------------+-------------------------
1 | Kopral Jono | Jalan jalan pelan pelan
2 | Paman Goble | Jalan Rusak
(2 rows)
postgres@myhost:~$ psql -d $MASTERDBNAME -c "delete from testtable where nomor = 1"
DELETE 1
postgres@myhost:~$ psql -d $SLAVEDBNAME -p 5433 -c "select * from testtable;"
nomor | nama | alamat
-------+-------------+-------------
2 | Paman Goble | Jalan Rusak
(1 row)
Yang akan datang: Replikasi PostgreSQL 9


